
Đề bài

Task
Task 1: Ye Ol' Search Engine
Google có lẽ là ví dụ nổi tiếng nhất về “công cụ tìm kiếm”; ý tôi là còn ai nhớ Ask Jeeves không? rùng mình
Giờ giải thích cách các “công cụ tìm kiếm” hoạt động có thể hơi mang tính dạy đời, nhưng đằng sau hậu trường còn nhiều thứ diễn ra hơn hẳn những gì ta thấy. Quan trọng hơn, ta có thể tận dụng điều này để tìm ra đủ thứ mà một wordlist không thể. Việc nghiên cứu nói chung - đặc biệt trong bối cảnh an ninh mạng - bao trùm gần như mọi việc bạn làm với tư cách một pentester. MuirlandOracle đã tạo một “room” tuyệt vời về cách hình thành tư duy nghiên cứu và chính xác bạn có thể thu được những thông tin gì từ việc đó.
Các “công cụ tìm kiếm” như Google thực chất là những bộ lập chỉ mục khổng lồ - cụ thể là lập chỉ mục nội dung được phân tán trên toàn bộ World Wide Web.
Những thành phần cốt lõi phục vụ việc lướt web này sử dụng “crawler” hay “spider” để truy tìm nội dung khắp World Wide Web; tôi sẽ bàn kỹ hơn ở nhiệm vụ tiếp theo.
Task 2: Let's Learn About Crawlers
Crawler là gì và chúng hoạt động như thế nào?
Các crawler khám phá nội dung theo nhiều cách. Một cách là phát hiện thuần túy: crawler truy cập một URL, rồi trả về cho công cụ tìm kiếm thông tin về loại nội dung của website đó. Thực tế, crawler hiện đại thu thập rất nhiều dạng thông tin - nhưng chúng ta sẽ bàn việc chúng được sử dụng ra sao ở phần sau. Một phương thức khác là crawler sẽ theo mọi URL tìm thấy từ các website đã được thu thập trước đó. Theo một nghĩa nào đó, chúng giống như virus: muốn “duyệt/lan” tới mọi thứ có thể.
Hãy hình dung một chút…
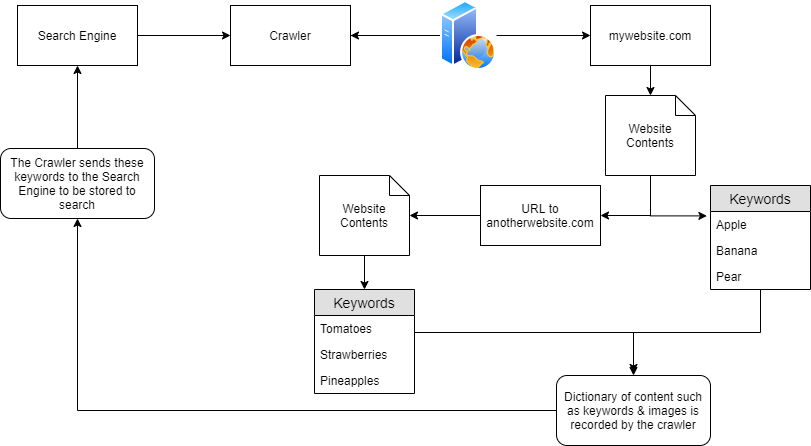
Sơ đồ dưới đây là một trừu tượng cấp cao về cách các web crawler hoạt động. Khi một web crawler phát hiện một miền như mywebsite.com, nó sẽ lập chỉ mục toàn bộ nội dung của miền, tìm kiếm các từ khóa và những thông tin linh tinh khác - phần “linh tinh” này tôi sẽ bàn sau.

Trong sơ đồ trên, “mywebsite.com” được thu thập với các từ khóa “Apple”, “Banana” và “Pear”. Các từ khóa này được lưu trong “từ điển” của crawler, sau đó trả về cho công cụ tìm kiếm (ví dụ Google). Nhờ tính bền vững này, Google giờ biết rằng miền “mywebsite.com” có các từ khóa “Apple”, “Banana” và “Pear”. Vì mới chỉ có một website được crawl, nếu người dùng tìm “Apple”… “mywebsite.com” sẽ xuất hiện. Hành vi tương tự xảy ra khi người dùng tìm “Banana”: vì nội dung đã lập chỉ mục báo rằng miền có “Banana”, nó sẽ được hiển thị cho người dùng.
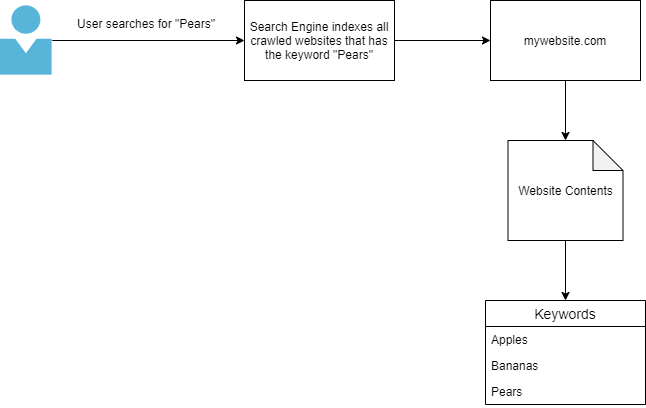
Như minh họa bên dưới, một người dùng gửi truy vấn “Pears” tới công cụ tìm kiếm. Vì công cụ tìm kiếm chỉ có nội dung của một website đã được crawl với từ khóa “Pears”, đó sẽ là miền duy nhất được hiển thị cho người dùng.

Tuy nhiên, như đã nói, crawler cố gắng “traverse” (duyệt), hay “crawl”, mọi URL và tệp mà chúng tìm thấy! Giả sử “mywebsite.com” vẫn có các từ khóa như trước (“Apple”, “Banana” và “Pear”), nhưng còn có một URL trỏ tới website khác “anotherwebsite.com”, thì crawler sẽ cố gắng duyệt mọi thứ tại URL đó (anotherwebsite.com) và lần lượt lấy nội dung của mọi thứ trong miền đó.
Điều này được minh họa ở sơ đồ dưới đây. Crawler ban đầu tìm thấy “mywebsite.com”, nơi nó crawl nội dung và thu được các từ khóa (“Apple”, “Banana” và “Pear”) như trước, nhưng lần này còn tìm thấy một URL ngoài. Khi crawl xong “mywebsite.com”, nó sẽ tiếp tục crawl nội dung của “anotherwebsite.com”, nơi nó tìm thấy các từ khóa (“Tomatoes”, “Strawberries” và “Pineapples”). “Từ điển” của crawler giờ chứa nội dung của cả “mywebsite.com” và “anotherwebsite.com”, rồi được lưu trữ trong công cụ tìm kiếm.
Tóm tắt
Tóm lại, công cụ tìm kiếm giờ biết về hai miền đã được crawl:
- mywebsite.com
- anotherwebsite.com
Lưu ý rằng “anotherwebsite.com” chỉ được crawl vì nó được tham chiếu bởi miền đầu tiên “mywebsite.com”. Nhờ tham chiếu này, công cụ tìm kiếm biết những điều sau về hai miền:
| Domain Name | Keyword |
| mywebsite.com | Apples |
| mywebsite.com | Bananas |
| mywebsite.com | Pears |
| anotherwebsite.com | Tomatoes |
| anotherwebsite.com | Strawberries |
| anotherwebsite.com | Pineapples |
Như minh họa phía dưới:
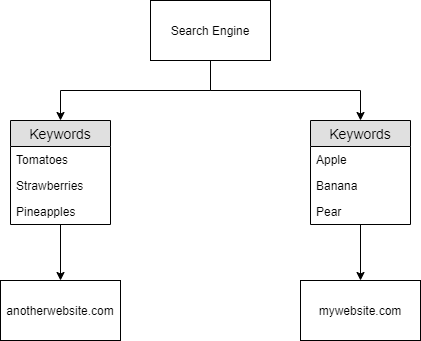
Giờ công cụ tìm kiếm đã có một chút kiến thức về từ khóa, giả sử người dùng tìm “Pears” thì miền “mywebsite.com” sẽ được hiển thị - vì đó là miền duy nhất đã được crawl có chứa “Pears”.
Tương tự, nếu người dùng tìm “Strawberries”, miền “anotherwebsite.com” sẽ được hiển thị, vì đó là miền duy nhất mà công cụ tìm kiếm đã crawl có chứa từ khóa “Strawberries”.

Tuyệt… nhưng còn thứ tự hiển thị thì sao?
Điều này rất hay… nhưng hãy tưởng tượng một website có nhiều URL ngoài (thường là vậy!). Điều đó sẽ đòi hỏi rất nhiều hoạt động crawl. Luôn có khả năng một website khác có thông tin tương tự như website đã được crawl - đúng không? Vậy “công cụ tìm kiếm” quyết định thứ bậc (hierarchy) của các miền hiển thị cho người dùng như thế nào?
Trong sơ đồ bên dưới, nếu người dùng tìm từ khóa “Tomatoes” (cả website 1–3 đều có), ai quyết định website nào được hiển thị trước, sau?
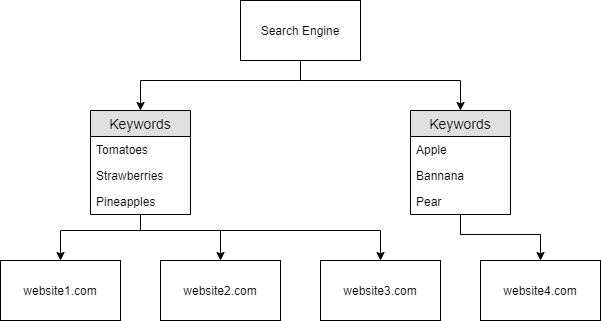
Một suy đoán “logic” có thể là website 1 → 3 sẽ được hiển thị theo thứ tự đó… Nhưng ngoài đời, các miền không hoạt động và/hoặc không được đặt tên như vậy.
Vậy ai (hay cái gì) quyết định thứ bậc? Ờ thì…
Trả lời câu hỏi
Task 3: Enter: Search Engine Optimisation
Tối ưu hóa công cụ tìm kiếm (SEO)
Tối ưu hóa công cụ tìm kiếm, hay SEO, là một chủ đề phổ biến và “hái ra tiền” trong các công cụ tìm kiếm hiện đại. Thậm chí đến mức cả những doanh nghiệp chuyên sống nhờ việc cải thiện “thứ hạng” SEO của một miền. Ở góc nhìn trừu tượng, công cụ tìm kiếm sẽ “ưu tiên” những miền dễ lập chỉ mục hơn. Có nhiều yếu tố quyết định một miền “tối ưu” đến mức nào - dẫn tới cơ chế giống như hệ thống chấm điểm.
Để nêu vài yếu tố ảnh hưởng tới cách chấm điểm, có thể kể đến:
- Độ phản hồi của website với các loại trình duyệt khác nhau, ví dụ Google Chrome, Firefox và Internet Explorer — bao gồm cả trên điện thoại di động!
- Mức độ dễ dàng để crawler có thể thu thập website của bạn (hoặc thậm chí là có cho phép thu thập hay không… phần này sẽ bàn sau) thông qua việc dùng “Sitemaps”.
- Loại từ khóa mà website của bạn có (ví dụ trong các ví dụ của chúng ta, nếu người dùng tìm truy vấn như “Colours” thì sẽ không có miền nào được trả về - vì công cụ tìm kiếm (chưa) crawl được miền nào có từ khóa liên quan đến “Colours”).
Có rất nhiều phức tạp trong cách từng công cụ tìm kiếm riêng lẻ “chấm điểm” hay xếp hạng các miền - bao gồm các thuật toán đồ sộ. Dĩ nhiên, các công ty vận hành công cụ tìm kiếm như Google không chia sẻ chính xác cách thức cuối cùng tạo ra thứ bậc các miền. Dù vậy, vì đây rốt cuộc vẫn là doanh nghiệp, bạn có thể trả tiền để quảng cáo/đẩy thứ tự hiển thị của miền mình.
Có nhiều công cụ trực tuyến - đôi khi do chính nhà cung cấp công cụ tìm kiếm phát hành - giúp bạn xem miền của mình được tối ưu hóa ra sao. Ví dụ, hãy dùng “Site Analyser” của Google để kiểm tra điểm của TryHackMe:


Theo công cụ này, TryHackMe có điểm SEO là 85/100 (tính đến 14/11/2020). Không tệ, và công cụ cũng hiển thị các lý do giải thích cách điểm số đó được tính ngay bên dưới trang.
Nhưng… Ai hay cái gì “quản lý” các Crawler?
Ngoài các công cụ tìm kiếm cung cấp “crawler”, chính chủ sở hữu website/web server mới là người quy định cuối cùng về những nội dung mà “crawler” được phép thu thập. Công cụ tìm kiếm sẽ muốn lấy mọi thứ từ một website - nhưng có vài trường hợp chúng ta không muốn toàn bộ nội dung trang được lập chỉ mục! Bạn nghĩ ra ví dụ nào không…? Chẳng hạn một trang đăng nhập quản trị bí mật. Chúng ta không muốn ai cũng tìm được thư mục đó - đặc biệt là thông qua tìm kiếm Google.
Giới thiệu robots.txt…
Trả lời câu hỏi

Task 4: Beepboop - Robots.txt
Robots.txt
Tương tự “Sitemaps” (sẽ bàn sau), đây là tệp đầu tiên được “Crawler” lập chỉ mục khi truy cập một website.
Nhưng robots.txt là gì?
Tệp này phải được phục vụ ở thư mục gốc của website - do chính webserver quy định. Nhìn phần đuôi .txt, có thể đoán ngay đây là một tệp văn bản.
Tệp văn bản này định nghĩa quyền hạn mà “Crawler” có đối với website. Ví dụ: loại “Crawler” nào được phép (vd. bạn chỉ muốn “Crawler” của Google lập chỉ mục trang của mình chứ không phải của MSN). Hơn nữa, robots.txt có thể chỉ ra những tệp và thư mục nào được hoặc không được “Crawler” lập chỉ mục.
Một mẫu robots.txt cơ bản như sau:

Các từ khóa chính:
| Từ khóa | Chức năng |
| User-agent | Chỉ định loại “Crawler” được phép lập chỉ mục (dấu * là wildcard: cho mọi crawler) |
| Allow | Chỉ định thư mục/tệp được lập chỉ mục |
| Disallow | Chỉ định thư mục/tệp không được lập chỉ mục |
| Sitemap | Chỉ vị trí sitemap (cải thiện SEO như đã nói; chi tiết về sitemap ở phần sau) |
Trong ví dụ trên:
- Bất kỳ “Crawler” nào cũng có thể lập chỉ mục trang.
- “Crawler” được phép lập chỉ mục toàn bộ nội dung trang.
- “Sitemap” nằm tại http://mywebsite.com/sitemap.xml.
Giả sử ta muốn ẩn một số thư mục hoặc tệp khỏi “Crawler”? Robots.txt hoạt động theo cơ chế danh sách đen (blacklist). Về cơ bản, trừ khi bị cấm, “Crawler” sẽ cố lập chỉ mục mọi thứ nó tìm thấy.
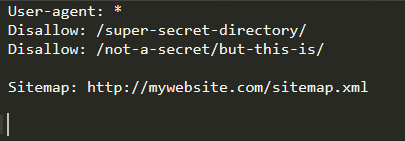
Trong trường hợp này:
- Bất kỳ “Crawler” nào cũng có thể lập chỉ mục trang.
- “Crawler” có thể lập chỉ mục mọi thứ khác không nằm trong /super-secret-directory/.
“Crawler” cũng phân biệt được thư mục con, thư mục và tệp. Như ở dòng Disallow thứ hai (/not-a-secret/but-this-is/):
- “Crawler” sẽ lập chỉ mục mọi nội dung trong /not-a-secret/,
- nhưng không lập chỉ mục bất cứ gì bên trong thư mục con /but-this-is/.
- “Sitemap” nằm tại http://mywebsite.com/sitemap.xml.
Nếu ta chỉ muốn một số “Crawler” nhất định được lập chỉ mục?
Ta có thể quy định như sau:

Diễn giải:
- “Crawler” Googlebot được phép lập chỉ mục toàn bộ trang (Allow: /).
- “Crawler” msnbot không được phép lập chỉ mục trang (Disallow: /).
Còn nếu muốn ngăn tệp khỏi bị lập chỉ mục?
Bạn có thể liệt kê thủ công từng phần mở rộng tệp không muốn bị lập chỉ mục - nhưng sẽ phải chỉ rõ thư mục chứa và tên đầy đủ của tệp. Với website lớn thì rất phiền. Đây là lúc có thể dùng một chút regex.
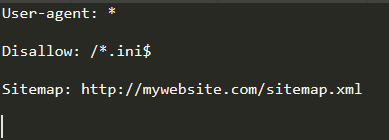
Trong ví dụ này:
- Bất kỳ “Crawler” nào cũng có thể lập chỉ mục trang.
- Tuy nhiên, “Crawler” không được lập chỉ mục bất kỳ tệp nào có đuôi .ini ở mọi thư mục/thư mục con (ký hiệu "$" neo về cuối chuỗi).
- “Sitemap” nằm tại http://mywebsite.com/sitemap.xml.
Vì sao muốn ẩn tệp .ini, chẳng hạn? Vì những tệp này thường chứa thông tin cấu hình nhạy cảm. Bạn có thể nghĩ thêm các định dạng tệp khác cũng có thể chứa thông tin nhạy cảm không?
Trả lời câu hỏi

Task 5: Sitemaps
Sitemaps
Tương tự như bản đồ địa lý ngoài đời thực, “Sitemap” cũng là bản đồ - nhưng dành cho website!
“Sitemaps” là những tài nguyên gợi dẫn hữu ích cho các crawler, vì chúng chỉ ra các tuyến đường cần thiết để tìm nội dung trên một miền. Hình minh họa dưới đây là ví dụ tốt về cấu trúc của một website và cách nó có thể trông như trên một “Sitemap”:
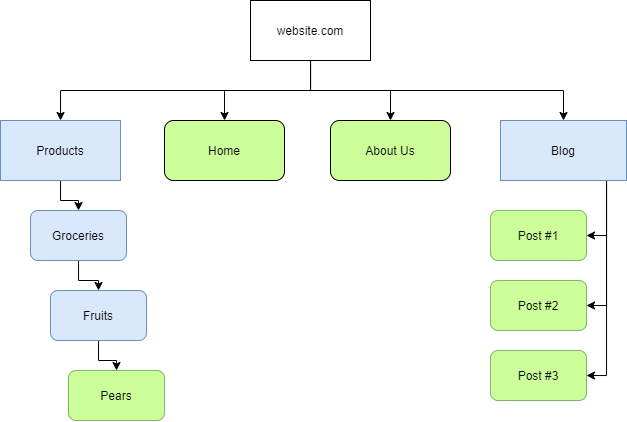
Các hình chữ nhật màu xanh biểu thị tuyến đường đến nội dung lồng nhau, giống như một thư mục, ví dụ “Products” của một cửa hàng. Còn các hình chữ nhật bo tròn màu xanh lục biểu thị một trang thực sự. Tuy nhiên, đây chỉ là để minh họa - ngoài thực tế “Sitemaps” không trông như vậy. Chúng sẽ giống với thứ này hơn:

“Sitemaps” được định dạng bằng XML. Tôi sẽ không giải thích cấu trúc định dạng tệp này vì “room” XXE do falconfeast tạo đã làm việc đó rất xuất sắc.
Sự hiện diện của “Sitemaps” có trọng lượng đáng kể trong việc ảnh hưởng đến mức “tối ưu hóa” và độ được ưu ái của một website. Như ta đã bàn trong phần “Search Engine Optimisation”, các bản đồ này khiến việc “traversal” (duyệt qua) nội dung của crawler dễ dàng hơn nhiều!
Vì sao “Sitemaps” được các công cụ tìm kiếm ưa chuộng?
Công cụ tìm kiếm “lười” mà! Nói đúng hơn - chúng có quá nhiều dữ liệu phải xử lý. Tính hiệu quả của cách thu thập dữ liệu là tối quan trọng. Những tài nguyên như “Sitemaps” cực kỳ hữu ích cho “Crawlers” vì các tuyến đường cần thiết tới nội dung đã có sẵn! Tất cả những gì crawler phải làm là thu thập nội dung đó - thay vì phải tự tay tìm và thu thập. Hãy nghĩ nó như việc dùng wordlist để tìm tệp thay vì đoán tên ngẫu nhiên!
Website càng dễ “crawl” thì càng được tối ưu cho “Search Engine”.
Trả lời câu hỏi

Task 6: What is Google Dorking?
Sử dụng Google để tìm kiếm nâng cao
Như đã bàn trước đó, Google đã crawl và lập chỉ mục vô số website. Người dùng bình thường hay dùng Google để tìm ảnh mèo (còn tôi thì “team chó”…). Dù Google có sẵn cả rổ ảnh mèo để phục vụ Joe, đó vẫn là cách dùng khá “cơ bản” so với những gì ta thật sự có thể khai thác.
Ví dụ, ta có thể thêm các toán tử (tựa như trong ngôn ngữ lập trình) để tăng/giảm số kết quả - thậm chí làm phép tính toán ngay trên Google!

Nếu muốn thu hẹp truy vấn, ta dùng dấu ngoặc kép. Google sẽ hiểu toàn bộ chuỗi bên trong ngoặc kép là chính xác và chỉ trả về kết quả chứa đúng cụm đó… Rất hữu ích để lọc bớt “rác”, như minh họa dưới đây.

Tinh chỉnh truy vấn
Ta có thể dùng các từ khóa như site: (ví dụ bbc.co.uk) cùng một truy vấn (ví dụ "gchq news") để tìm trên một trang cụ thể, giúp lọc bớt nội dung khó tìm theo cách thông thường. Chẳng hạn, với site: và từ khóa "bbc" và "gchq", ta thay đổi thứ tự kết quả Google trả về.
Trong ảnh chụp, tìm “gchq news” cho ~1.060.000 kết quả. Trang ta muốn lại đứng sau trang chính thức của GCHQ.

Nhưng ta không muốn thế… Ta muốn “bbc.co.uk” hiện trước, nên hãy tinh chỉnh truy vấn với site:. Hãy chú ý: Google trả về ít kết quả hơn? Trang ta không muốn đã biến mất, chỉ còn trang đúng ý!

Dĩ nhiên, với chủ đề “GCHQ” đang được bàn tán nhiều, sẽ luôn có rất nhiều kết quả.
Vì sao “Google Dorking” hấp dẫn?
Trước hết - và quan trọng nhất - nó hợp pháp! Đây đều là thông tin công khai đã được lập chỉ mục. Tuy nhiên, bạn dùng vào việc gì mới là chỗ phát sinh vấn đề pháp lý…
Một vài từ khóa phổ biến có thể kết hợp:
| Từ khóa | Tác dụng |
| filetype: | Tìm tệp theo phần mở rộng (vd. PDF) |
| cache: | Xem bản Cached của Google với URL chỉ định |
| intitle: | Cụm từ bắt buộc xuất hiện trong tiêu đề trang |
Ví dụ, muốn dùng Google để tìm tất cả PDF trên bbc.co.uk:
site:bbc.co.uk filetype:pdf

Tuyệt! Ta đã tinh chỉnh để Google truy vấn mọi PDF công khai trên “bbc.co.uk” - Bạn khó mà tìm được những tệp kiểu “Freedom of Information Request Act” chỉ bằng một wordlist!
Ở đây ta dùng đuôi PDF, nhưng bạn nghĩ ra những định dạng tệp nhạy cảm nào khác có thể đang công khai không? (Thường là vô tình!!) Nhắc lại: bạn làm gì với kết quả mới là chỗ pháp lý lên tiếng - đó là lý do “Google Dorking” vừa hay vừa nguy hiểm.
Đây là ví dụ duyệt thư mục (directory traversal) đơn giản.
Mình đã che đi khá nhiều phần bên dưới để bảo vệ bạn, mình, THM và chủ sở hữu các miền.


Trả lời câu hỏi

'Labs > Information Gathering' 카테고리의 다른 글
| Intel101 Lab - CyberDefenders (0) | 2025.10.28 |
|---|---|
| Recon Badge - PentesterLab (0) | 2025.10.28 |
| Pentesting Fundamentals - TryHackMe (0) | 2025.10.27 |
| Sakura Room - TryHackMe (0) | 2025.10.27 |
| OhSINT - TryHackMe (0) | 2025.10.26 |